
如果每個品牌都在做內容,多做一篇文章為什麼幾乎沒用?
從內容衝擊、JTBD 選題、支柱—群集系統到 AI 搜尋顛覆,剖析內容過剩時代的進階經濟學與作業系統。
如果每個品牌都在做內容,多做一篇文章為什麼幾乎沒用?
入門篇告訴你:內容行銷的邏輯是「先創造價值、再贏得信任」,要對受眾有用、要一致、要陪伴顧客旅程。這些原則都對,但它們有一個尷尬的副作用——全世界的行銷人都同意這些原則,於是大家都在拚命產出內容。當每一個品類、每一個關鍵字底下都已經躺著上百篇「看起來很有用」的文章時,你再多寫一篇「新手完整指南」,邊際效益往往趨近於零。內容行銷正在進入一個經濟學家稱為「內容衝擊(Content Shock)」的階段:可被消費的內容供給呈指數成長,但人類可用來消費內容的注意力總量幾乎是固定的。
這就是進階內容行銷要面對的真問題。它不再問「內容好不好」,而問更尖銳的三件事:這篇內容是否真的填補了一個沒被滿足的需求?我的產出與發布是否能被系統化地放大,而不是一篇一篇手工堆砌?以及,當搜尋與資訊獲取的管道本身正在被 AI 改寫,我累積的內容資產還站得住嗎? 這篇文章假設你已經懂了內容行銷的基本定義、互惠與信任機制、以及它與 STP/4P 的接點——我們要往前一步,談內容的經濟學、作業系統與結構性風險。
內容衝擊:當供給爆炸,唯一的解方是「微分化」
「內容衝擊」這個概念由行銷作家 Mark Schaefer 在 2014 年提出,它的論證很簡單卻很有力:如果某個主題的內容供給持續增加,而受眾的注意力是稀缺且封頂的,那麼進入這個領域的邊際成本會愈來愈高,邊際報酬會愈來愈低,直到「再投入一塊錢內容,換不回一塊錢價值」。這不是要你別做內容,而是逼你重新思考在哪裡做、為誰做。
Schaefer 給出的策略性回應,與經濟學的供需直覺一致:當一個市場供過於求,你有兩條路——要嘛把品質拉到競爭對手追不上的高度(這需要資源與時間),要嘛轉向一個供給還很稀薄的利基(niche)。對資源有限的品牌(尤其是新創與中小企業)來說,後者幾乎是唯一可行的路。與其在「咖啡」這個血流成河的紅海寫第一萬零一篇沖煮指南,不如在「給租屋族、沒有快煮壺、預算三千元以內的義式手沖入門」這種高度微分化(micro-segmented)的縫隙裡,成為那個小群體心中無可取代的權威。
這裡有一個對應入門 STP 的進階理解:內容行銷的市場區隔,往往要切得比產品的市場區隔更細。產品也許服務「所有上班族」,但內容若想突圍,必須對準上班族裡某個有強烈、具體、且尚未被好好回答之問題的次群體。微分化的代價是觸及人數變少,但回報是——在那個小池塘裡,你是大魚,而大魚能贏得的信任、口碑與「贏得媒體」擴散,遠超過在大海裡當一條沒人記得的小魚。
從「我想寫什麼」到「受眾想完成什麼」:JTBD 內容選題
入門篇提到要建立人物誌(Persona),釐清受眾是誰。進階的選題方法則更進一步,借用了 Clayton Christensen 的「待完成的工作(Jobs to Be Done, JTBD)」理論:人們不是因為「我是某種人」而消費內容,而是因為「我此刻卡在某個進度上,需要一個工具把我推進到下一步」。
這個轉換很關鍵。Persona 容易讓人停在人口統計與興趣標籤(「25–35 歲、都會、喜歡咖啡」),但 JTBD 逼你問:這個人是在什麼情境下,帶著什麼任務,來尋找這篇內容的? 同一個人在「我剛搬新家想知道要買哪台咖啡機」與「我手邊的咖啡機壞了急著找替代方案」這兩個情境下,需要的內容完全不同,搜尋的字眼也不同。內容選題若鎖定「工作」而非「人」,命中率會高得多。
實務上有一個很好用的對照框架,把搜尋行為背後的「工作」分成四類搜尋意圖(Search Intent):
- 資訊型(Informational):「想搞懂某件事」——對應認知階段,適合科普、教學、概念解釋。
- 導航型(Navigational):「想找某個特定品牌或頁面」——通常已經知道你是誰。
- 商業調查型(Commercial Investigation):「想比較、想確認哪個方案適合我」——對應考慮階段,適合評測、比較表、選購指南。
- 交易型(Transactional):「準備行動了」——對應決策階段,適合試用、報價、規格。
進階內容團隊不會把所有資源壓在某一類,而是依漏斗階段刻意配置:用大量資訊型內容把「池子」做大、贏得認知,用商業調查型內容承接正在比較的人、贏得信任,再用少量交易型內容收網。這也修正了一個常見的迷思——「只寫接近成交的內容才有用」。事實上,若沒有前段資訊型內容把陌生人引進來,後段的轉換內容根本沒有人可收。
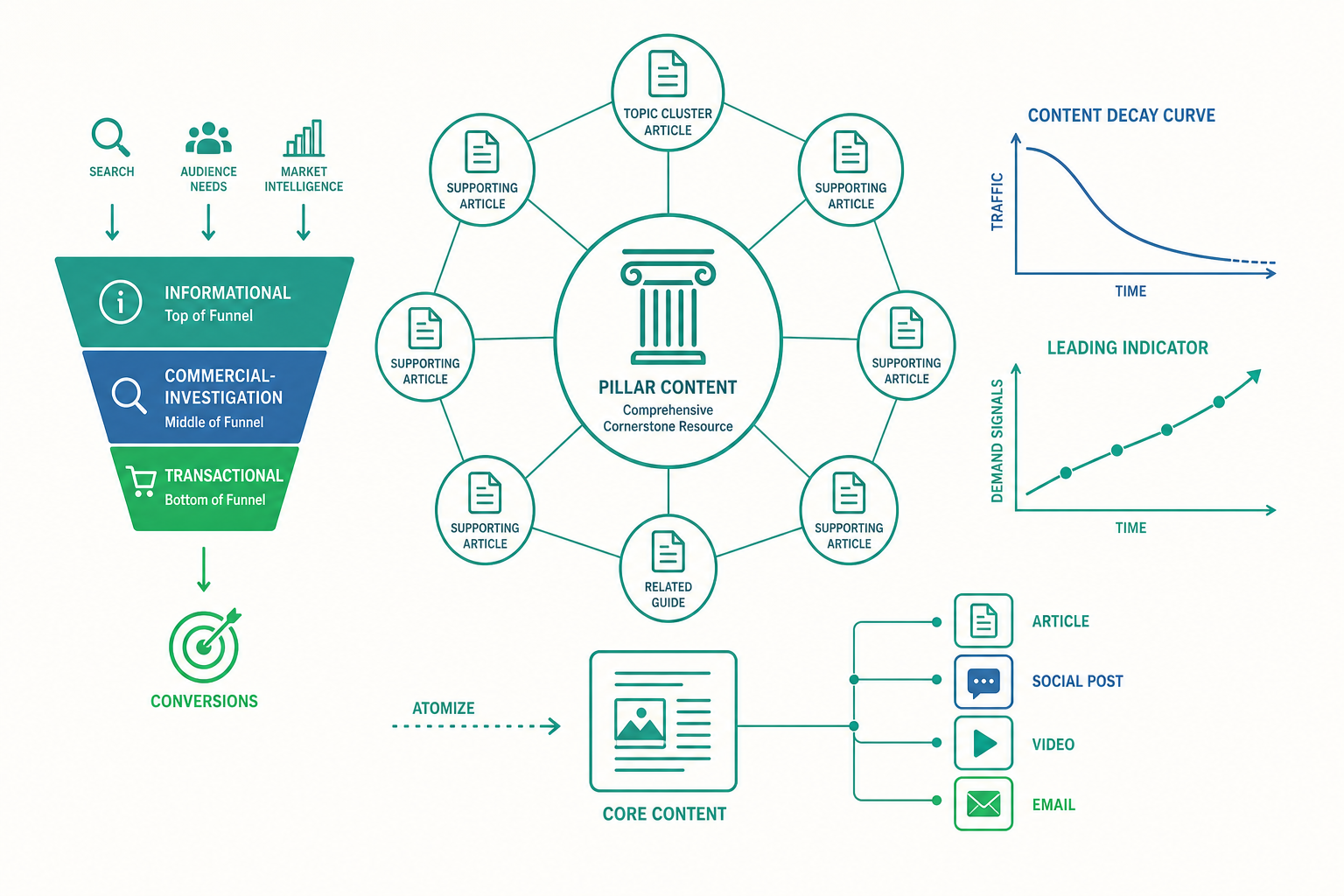
內容作業系統:支柱—群集模型與內容原子化
入門篇強調「一致性」與「穩定產出節奏」,但沒有回答一個營運上的硬問題:當你要長期、規模化地產出內容,如何避免變成一團各自為政、彼此不相干的散文堆? 進階內容行銷的答案,是把內容當成一個有結構的系統來經營,而不是一篇篇孤立的作品。
最廣為採用的結構是「支柱—群集模型(Pillar–Cluster Model)」,又稱主題叢集(Topic Cluster)。它的設計是:
- 支柱頁(Pillar Page):針對一個寬廣的核心主題,做一篇全面、權威、長篇的總覽頁(例如「內容行銷完整指南」)。
- 群集內容(Cluster Content):圍繞這個支柱,產出一系列深入單一子題的文章(「如何寫支柱頁」「內容如何衡量」「JTBD 選題法」……)。
- 內部連結(Internal Linking):每篇群集內容都連回支柱頁,支柱頁也連向各群集——形成一張彼此強化的網。
這個結構同時服務三個目的。對受眾,它讓人能從一個入口深入整個主題,停留更久、信任更深;對搜尋引擎,密集且有組織的內部連結會傳遞「這個品牌在這個主題上具有權威」的訊號,有助於整組頁面的排名;對內容團隊自己,它把「下一篇該寫什麼」從靈感問題變成了地圖問題——只要盤點支柱底下還有哪些子題沒覆蓋即可。
另一個與之搭配的進階作業概念是「內容原子化(Content Atomization)」或「一次創作、多形態發布(Create Once, Publish Everywhere, COPE)」。它的洞見是:內容生產的真正瓶頸不是「想法」,而是「形態轉換」。一份紮實的研究報告或一場深度訪談,可以被拆解、重組成部落格長文、十則社群貼文、一支短影音腳本、一封電子報、一張資訊圖表。回到入門篇的自有、付費、贏得媒體框架——原子化讓同一份核心智慧資產,得以低成本地鋪滿多個自有與社群通路,最大化每一分創作投入的回報。這也是為什麼成熟團隊的產出看起來「量很大」,但背後其實是少數高品質核心內容的反覆裂變,而非無止盡地從零生產。
衡量的進階:領先指標、內容衰退與單位經濟
入門篇說「衡量不能少」,並列了觸及、互動、轉換等指標。進階的衡量觀,要處理三個入門少談的難題。
第一,分清領先指標與落後指標(Leading vs. Lagging Indicators)。 銷售與營收是落後指標——它們反映的是過去努力的結果,等你看到它變動時,能改變它的行動早已發生。聰明的內容團隊會同時盯著領先指標:自然搜尋的曝光與排名變化、電子報訂閱成長率、回訪率、內容輔助轉換(assisted conversion)。這些指標會比營收更早反應內容策略的好壞,讓你能在落後指標惡化之前就修正方向。只用營收評估內容,等於只看後照鏡開車。
第二,內容會衰退(Content Decay)。 內容資產不是一勞永逸的。一篇曾經排名第一的文章,會因為資訊過時、競爭對手推出更好的版本、或搜尋演算法改變而逐漸流失流量,這個現象稱為內容衰退。這帶出一個反直覺但極重要的進階實務——「歷史最佳化(Historical Optimization)」:與其永遠在生產新內容,不如定期回頭更新、強化那些曾經表現好但正在下滑的舊內容,投資報酬率往往遠高於從零寫新文章。換句話說,內容組合需要像投資組合一樣被「再平衡」,而不是只進不出。
第三,回到單位經濟(Unit Economics)。 內容行銷最終要能回答商業問題:產出一份內容的全成本(人力、製作、推廣)是多少?它在生命週期內帶來的價值(流量、名單、輔助成交)又是多少?這牽涉到把入門提過的歸因(Attribution)難題,從「哪一次點擊該記功」進一步推到「這整條內容策略的投資報酬率(ROI)是否為正」。承認衡量有其極限是誠實的,但「難以精確歸因」不該被當成「不必衡量」的藉口——它只是要求我們用更聰明、組合式的指標來逼近真相。
看一個例子
讓我們用一個假想但貼近現實的情境,把這些進階概念串起來。
「沃土知識」是一個專做 B2B 數據分析軟體的新創。它的入門級內容行銷做得不差——部落格上有不少「什麼是數據儀表板」之類的科普文,但團隊發現一個尷尬的事實:流量年年成長,潛在客戶名單卻幾乎沒動。
用進階視角拆解,問題立刻浮現。第一,他們犯了內容衝擊的錯——在「數據分析」這個被巨頭佔滿的紅海裡寫泛泛科普,永遠排在大公司後面,吸來的也多是隨手一查就走的學生與好奇者,不是會買單的人。第二,他們的選題停在 Persona(「數據分析師」),沒進到 JTBD——分析師真正卡關的,是「我老闆要我證明這季行銷預算有效,但資料散在五個系統裡」這種具體任務。
新策略很明確:微分化 + 重排意圖配置。他們放棄寬泛科普,鎖定「中小企業行銷主管,要向老闆證明成效卻苦於資料分散」這個利基,圍繞它建一個支柱頁「行銷成效歸因完整指南」,底下長出一串群集內容(「如何串接五個廣告平台的資料」「該選哪種歸因模型」「給老闆看的報表怎麼做」),刻意加重商業調查型意圖的內容。一篇深度的「歸因模型比較」訪談,被原子化成長文、電子報、五則 LinkedIn 貼文與一支教學短片。
半年後,總流量其實只小幅成長,但領先指標全面好轉:電子報訂閱翻倍、回訪率上升、來自「比較」類內容的試用申請明顯增加。一年後,落後指標——付費轉換——終於跟上。對照前面的概念:他們用微分化跳出內容衝擊、用 JTBD 校準選題、用支柱—群集把散文變成系統、用原子化放大每份產出,最後用領先指標提早確認方向對了。這條路依然需要耐心,但它把「多寫文章」這個體力活,換成了「設計內容系統」的策略活。
重點回顧
- 內容衝擊是進階內容行銷的起點:當內容供給爆炸而注意力固定,多寫一篇的邊際效益趨近於零;資源有限者的解方是微分化,在供給稀薄的利基裡當大魚,而非在紅海裡當小魚。
- 選題要從 Persona 進到 JTBD:對準受眾「在什麼情境、想完成什麼工作」,並依資訊型/商業調查型/交易型等搜尋意圖刻意配置漏斗各階段的內容,而非只押注接近成交的內容。
- 把內容當系統經營:用支柱—群集模型讓內容彼此強化、傳遞主題權威,用內容原子化讓一份核心資產裂變成多形態、鋪滿多通路,最大化每分創作投入的回報。
- 衡量要看領先指標、管理內容衰退:營收是落後指標,須同時盯排名、訂閱、回訪等領先指標;內容會衰退,歷史最佳化(更新舊內容)的報酬常高於新增,內容組合需像投資組合般再平衡。
- 承認歸因的極限,但不放棄衡量:把問題從「哪次點擊記功」推到「整條策略的單位經濟與 ROI 是否為正」,用組合式指標逼近真相。
深入探討(研究所視角)
對有志深入的學習者,進階內容行銷有幾條值得追索的前沿脈絡。
第一,生成式 AI 對「內容可發現性」的結構性顛覆。 入門篇提過零點擊搜尋(Zero-click Search),進階的問題更尖銳:當愈來愈多人從 AI 對話助手(而非搜尋結果頁)獲得答案,內容的「被發現」邏輯正從「搜尋引擎最佳化(SEO)」轉向業界新創的「生成式引擎最佳化(Generative Engine Optimization, GEO)」或「答案引擎最佳化(Answer Engine Optimization, AEO)」——也就是優化內容,讓它更可能被大型語言模型(LLM)擷取、理解並引用為答案來源。這引出一連串尚無定論的研究議題:當 AI 摘要攔截了多數流量,內容創作的商業誘因會如何改變?哪一類內容(第一手數據、深度體驗、難以被摘要取代的觀點)會升值,哪一類(可被輕易複述的泛泛科普)會崩盤?這是橫跨資訊檢索、平台經濟與行銷策略的活躍前沿。
第二,內容市場的「檸檬市場」風險。 經濟學家 George Akerlof 的「檸檬市場(Market for Lemons)」理論指出:當買方無法事先分辨品質好壞,劣質品會把優質品逐出市場。生成式 AI 把內容的生產成本壓到趨近於零,使網路面臨大量「看起來合理、實則空洞」內容的洪水。值得研究的是:在這種資訊環境裡,信任的訊號(trust signal)會如何重新定價?品牌的第一手研究、可驗證的數據、真實的專家署名、難以偽造的社群關係,是否會因為稀缺而成為新的競爭壁壘?這把內容行銷從「產製技巧」推進到「資訊品質的訊號賽局」這個更深的層次。
第三,注意力的倫理與「黑暗模式」的邊界。 進階內容團隊掌握了愈來愈精細的工具——A/B 測試標題、依行為數據觸發內容、用個人化演算法延長停留——但這些能力同時逼近一條倫理紅線。當「最佳化參與度」變成壓倒性的目標,內容設計可能滑向操弄性的「黑暗模式(Dark Patterns)」:誘導性訂閱、難以退訂的電子報、刻意製造焦慮以促成行動。對研究所階段的學習者而言,這提出一個必須正面回答的問題——「贏得注意力」與「剝削注意力」之間的界線在哪裡? 內容行銷愈成熟、工具愈強大,這條界線就愈需要被嚴肅地、跨越行銷、傳播倫理與公共政策地反覆檢視。